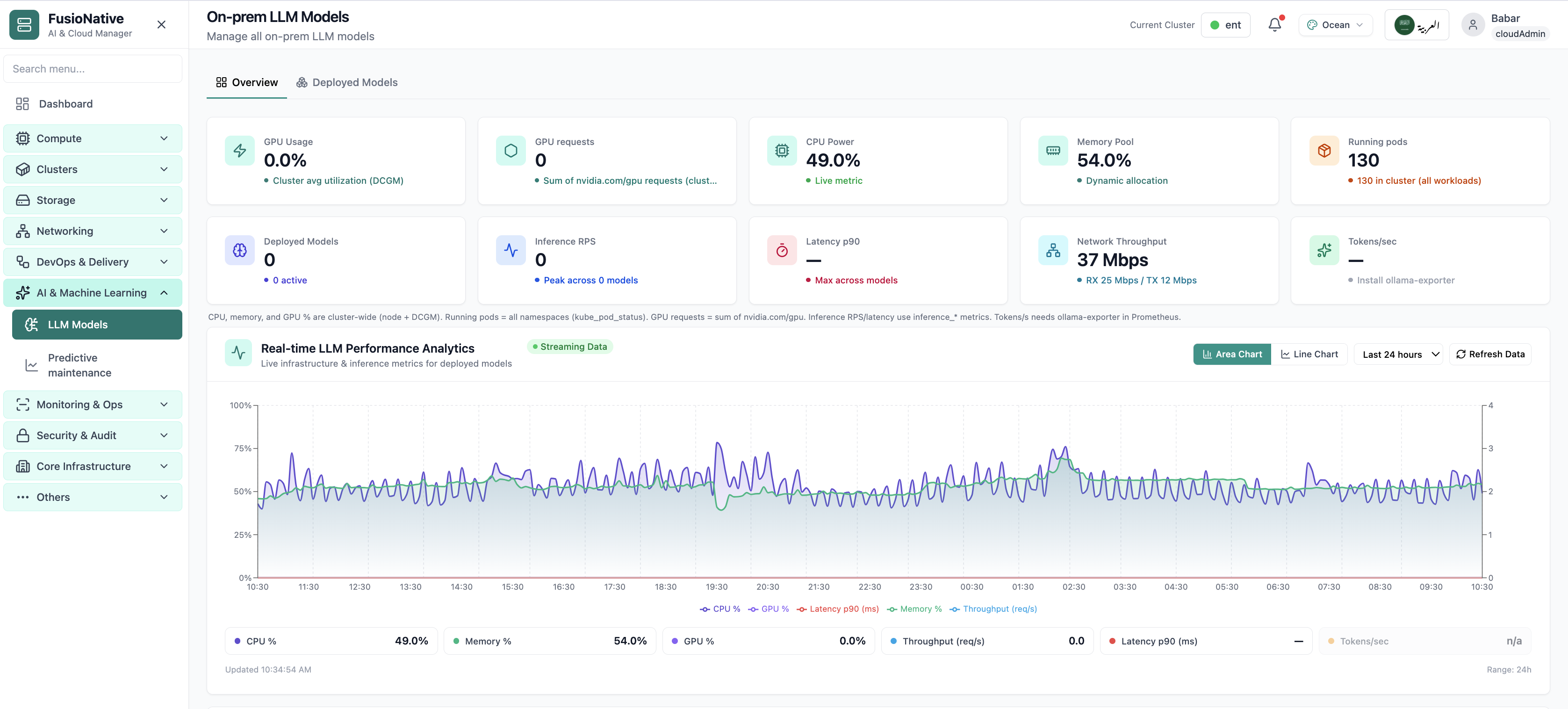
AI & GPU metrics
GPU and LLM performance metrics from the on-prem AI workspace. This is the same interface your team uses in production.
- GPU and cluster metrics on one screen
- Click to zoom in without losing detail
- Works alongside the rest of Cloud Admin
Click the screenshot to open full size, zoom, and pan.